今回の記事はC#における構造体(struct)について。
複合的なデータを扱う際、多くの場面ではクラス(class)が用いられるかと思います。しかし、パフォーマンスが重要な場面や、GCによる影響が大きいUnityなどでは、状況に応じてクラスではなく構造体を使用した方が良いこともあります。
近年はC#においてもパフォーマンスが重視されるようになり、構造体が用いられる機会も多くなっています。またUnityのDOTSにおいても、C# Job SystemやBurst Compilerに最適化されたコードを書くために構造体を多用することになります。
ここでは構造体に関する基礎的な知識から、クラスと構造体のメモリ管理について、そして実際に構造体を用いる際の注意や活用方法についても解説していきたいと思います。
ただ今回の記事、調子に乗って色々な内容を詰め込んだ結果、めちゃくちゃに長くなってます。そのため、「そこまで詳しいことは要らないからとりあえず活用方法だけ知りたい!」という方は、とりあえずメモリ周りの部分は飛ばして他の部分から読んでみるといいかもしれません。ただし、きちんと構造体を使うためにはメモリ関連の知識は必要になります。
あと、この記事を書くにあたって参考にした資料として「Understanding C# Struct All Things」というneueccさんの素晴らしい講演があります。というかこの記事の内容の4〜5割ぐらいはこの講演から引っ張ってきたものなんで、構造体についてある程度理解している方であればこの記事読まなくてもそっち見て貰えば…というのはそうなんですが。
また、この記事でも触れますが、クラスと構造体の使い分けについては「クラスと構造体の使い分け」という記事を参考にしたので、そちらも合わせて読んでいただけると。
クラスと構造体の違い
詳しいことを見ていく前に、まずはクラスと構造体の違いから。
まず根本的な違いとして、クラスは参照型であるのに対し、構造体は値型です。両者の挙動の差はこの違いに起因します。構造体は値型であるため、参照型であるクラスと比較して機能にいくつかの制限がかかります。
それでは、具体的にどのような差があるのかを見ていきましょう。
コンストラクタと初期化
クラスの場合、参照型であるため変数の初期値はnullになります。また、クラスは引数なしのコンストラクタやフィールドの初期値を設定できます。
public class SampleClass
{
// 空のコンストラクタを定義可能
public SampleClass() { }
// フィールドに初期値を入れておくことも可能
public int a = 2;
public int b = 3;
}
SampleClass sample = default; // nullそれに対して構造体の場合は、すべてのメンバが0やfalseなどの規定値で初期化された状態になります。
また、C#9.0以下では空のコンストラクタを定義することはできず、フィールドの初期値を設定することもできませんでした。C#10.0以降ではこの制約が緩和され、上の機能が使用可能になっています。
public struct SampleStruct
{
public SampleClass(int a, int b)
{
this.a = a;
this.b = b;
}
// C#9.0では空のコンストラクタを定義できない (C#10.0以降では可能)
// public SampleClass() { }
public int a;
public int b;
// C#9.0ではフィールドに初期値を入れることはできない (これもC#10.0以降では可能)
// public int a = 1;
// public int b = 2;
}
SampleStruct sample = default; // 全て規定値(0)で初期化された状態
// newを書かなくてもそのまま利用可能
sample.a = 2;
sample.b = 3;継承
クラスにおいて用いられる継承ですが、構造体は他のクラス/構造体を継承することができません。例えば、以下のようなコードはコンパイルエラーになります。
public struct Foo
{
public int a;
public int b;
}
// 継承は不可。以下のコードはコンパイルエラーになる
public struct Bar : Foo // Type 'Foo' in interface list is not an interface (CS0527)
{
}継承が不可能なため、当然abstractやsealedも使用できません。
public abstract struct Foo { } // コンパイルエラー
public sealed struct Bar { } // コンパイルエラーただし、インターフェースを実装することは可能です。以下は、IEquatable<T>を実装したstructの例になります。
// structでもインターフェースを実装することは可能
public struct Foo : IEquatable<Foo>
{
public int a;
public int b;
public bool Equals(Foo other)
{
return this.a == other.a && this.b == other.b;
}
public override bool Equals(object obj)
{
if (obj is Foo foo) return Equals(foo);
else return false;
}
public override int GetHashCode()
{
return (a, b).GetHashCode();
}
}参照渡し/値渡し
両者を使い分ける際に重要なのは、引数として渡した時の挙動です。
まずはクラスの場合から見ていきましょう。クラスは参照型であるため、クラスの変数を引数として渡す際には参照が渡されます。(参照型の値渡し)
例えば以下のようなコードがあったとして…
// 適当なクラス
public class FooClass
{
public int a;
}
// foo.aを1加算する関数
void IncrementA(FooClass foo)
{
foo.a++;
}
// インスタンスを生成
var foo = new FooClass();
foo.a = 0;
// 関数にはfooの参照が渡される
IncrementA(foo);
// 1が表示される
Console.WriteLine(foo.a);これを実行すると、コンソールには1が表示されます。これは、引数としてfooの参照が渡されているためです。
では、これが構造体の場合にはどうなるでしょうか。試しにこのコードのFooClassをFooStructに置き換えてみます。
// 適当な構造体
public struct FooStruct
{
public int a;
}
// foo.aを1加算する関数、のはず...
void IncrementA(FooStruct foo)
{
foo.a++;
}
// インスタンスを生成
var foo = new FooStruct();
foo.a = 0;
// 引数にfooを渡しているので加算されるはずが...
IncrementA(foo);
// 0が表示される!!
Console.WriteLine(foo.a);こちらも1が表示されるかと思うかもしれませんが、実際にコンソールに表示される値は「0」になります。
構造体はintやfloatなどと同じく値型であるため、引数として渡されるのは参照ではなく「値のコピー」になります。(値型の値渡し)
そのため、いくら関数内で引数のFooStructを書き換えたとしても、値のコピーを書き換えているだけであるため元の変数には反映されません。このような性質を持つため、一般的に構造体はImmutable(不変)であることが推奨されます。
ただし、refキーワードを用いることで値型を参照渡しすることも可能です。例えば、先ほどのIncrementA関数の引数にrefを追加してみます。
// 引数にrefキーワードを追加
void IncrementA(ref FooStruct foo)
{
foo.a++;
}// インスタンスを生成
var foo = new FooStruct();
foo.a = 0;
// refをつけてfooを渡す (参照渡し)
IncrementA(ref foo);
// 1が表示される
Console.WriteLine(foo.a);このようにrefをつけることで、構造体の書き換えを参照型と同様に行うことが可能になります。
ただし、先ほども述べたように構造体は不変であることが望ましく、値を書き換えられないようにしておくべきです。このような場合には、構造体ではなくクラスを利用する方が良いでしょう。
[余談] Vector3.Set()の罠
ちょっとした余談ですが、Unityにはこのstructの性質とプロパティの組み合わせによって引き起こされる有名な罠があります。
UnityにはVector3という構造体が存在し、オブジェクトの位置やスケール等を扱うために使われています。
public struct Vector3
{
public float x;
public float y;
public float z;
...
}そして、このVector3にはSet(x, y, z)というメソッドが用意されています。
var vector3 = new Vector3(0, 0, 0);
vector3.Set(1, 2, 3);パッと見便利そう…なのですが、これがプロパティと組み合わさることで恐ろしい事態が発生します。
まずは以下のコードを見てください。
// さて何が起こるでしょう
transform.position.Set(1, 2, 3);では問題です。このコードを実行すると何が起きるでしょうか。
一見positionの値が書き換えられているように見えます。が、答えは「何も起こらない(!)」です。恐ろしいことに、このコードはコンパイルを問題なく通過し、実行時にも何のエラーも起きません。
このような事態を引き起こしている原因が、先ほど挙げた構造体の値渡しの性質です。
// 問題のトラップ
transform.position.Set(1, 2, 3);
// やってることは下のコードと同じ
transform.INTERNAL_get_position(out Vector3 value);
value.Set(1, 2, 3);Transformの値は実際にはUnity内部のC++部分にあり、transform.positionはそれにアクセスするためのプロパティに過ぎません。
そのため、transform.positionに対してSetを呼んでも、それは返ってきたコピーを書き換えているだけに過ぎず、実際の値は変更されません。
// これはコンパイルエラーになる (意味のない代入であるため)
transform.position.x = 10;上のように直接フィールドを書き換えようとする場合にはC#側がコンパイルエラーにしてくれるのですが、メソッド呼び出しに関してはエラーになりません。そのためにこんな罠が発生してしまっているわけです。
構造体が不変であることを推奨する理由はこのような混乱を避けるためです。自分で構造体を定義する際には、最初からreadonlyにしておくか、中身を変更するメソッドを置かないようにしておきましょう。
Vector3.Set()に関しては…Unity側にも色々事情があるんでしょ知らんけど。
ここまでのまとめ
・クラスは参照型、構造体は値型
・構造体はインターフェースのみ継承可
・構造体は値渡しであることに注意 (ref、inをつけると参照渡し)
・可能な限り構造体は不変にしておく
クラス/構造体におけるメモリ管理
クラスと構造体の挙動の違いについてわかったところで、次は内部的な違いについて見ていきましょう。
スタック(Stack)とヒープ(Heap)について
クラスと構造体の話に入る前に、まずはスタックとヒープによるメモリ管理について簡単に解説します。(かなりざっくりした説明になるので、詳しく知りたい場合は適宜調べてください。)
C#において、メモリの確保は「スタック領域」と「ヒープ領域」という2つの領域で行われます。
スタック(Stack)
スタック(Stack)はその名の通り、データを積み上げていくような方法でメモリを管理します。そのため、スタック上に確保したデータは確保した順に(積み上げた順に上から)解放されていくことになります。
例えば以下のようなコードがあった場合。
int a;
{
long b;
{
short c;
}
}スコープ内でローカル変数を宣言すると、順番にスタックに積まれていきます。
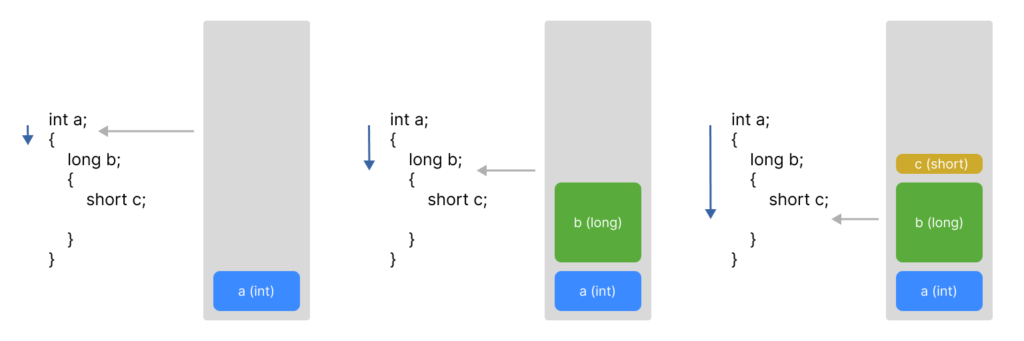
そして、スコープを抜けた時点でメモリが解放されます。
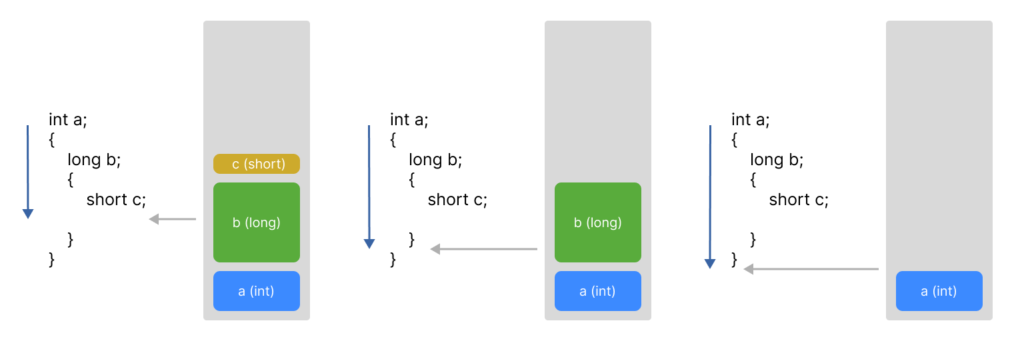
スコープ内でどれだけ確保したかを記憶しておくだけで良いため、スタックを用いたメモリ管理は効率が良く高速です。
しかし、スタック領域に確保できるデータ量は限られており、大きなデータを扱うのには向いていません。また、スタックはその性質上、明確にスコープがわかっているデータに対してしか利用できないという欠点もあります。
そのようなデータに関しては、スタックではなくヒープ上で管理することなります。
ヒープ(Heap)
ヒープ(Heap)はスタックとは異なり、任意のサイズのデータを任意の順番で確保/解放します。
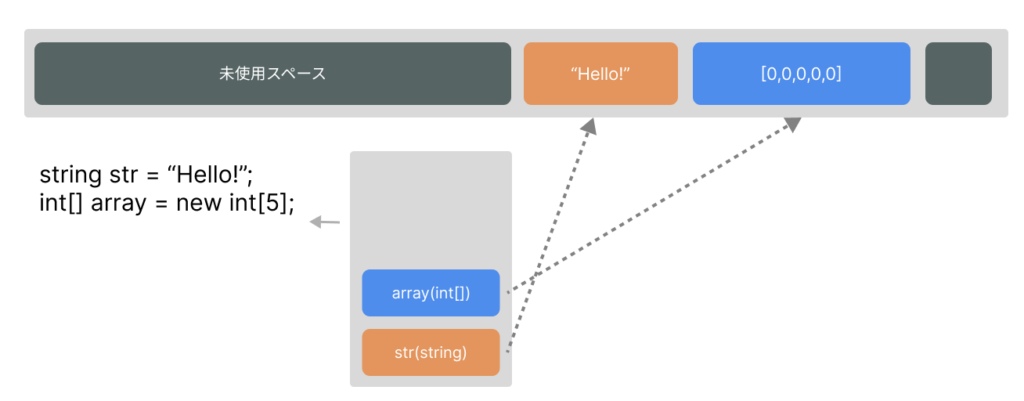
ヒープにはスタックのような制限がない分、メモリ管理の方法がスタックに比べて複雑であり、さらに領域の確保と解放を繰り返すことでデータがメモリ上に散在する「断片化」を引き起こします。断片化が起きることで空き容量を探す手間が増えるほか、キャッシュのヒット率が低下し処理速度が悪化します。そのため、ヒープへのアクセスはスタックに比べて遥かに低速です。
また、ヒープはスコープが不定であるため、使用が終わったタイミングで解放を行わないとメモリ上にゴミが残ってしまいます。(いわゆるメモリリーク)
C#ではこれを手動で解放する必要はなく、ガベージコレクション(GC)がこれを管理し、自動的に使用されなくなった(どこからも参照されなくなった)メモリの解放を行ってくれます。しかし、GCの回収は比較的高コストであり、特にGCの影響が激しいUnityでは動きがカクつく原因にもなります。
そのため、スタック上で管理可能なデータに関しては、可能な限りスタックを利用した方が処理性能は良くなります。
クラス/構造体とメモリ
少々長くなりましたが、クラスと構造体に話を戻します。
スタックの項目でも見た通り、C#ではローカル変数はスタック上に置かれます。この時、変数が「値型」である場合はすべてのデータがスタック上に置かれ、「参照型」である場合はヒープ上にデータの実体を置き、ヒープへの参照のみがスタック上に置かれます。つまり、スコープ内でnew()を用いてインスタンスを生成した場合、値型である構造体はスタック上に、参照型であるクラスはヒープ上に置かれることになります。
そのため、メモリの確保やアクセスに関しては構造体の方が高速であり、いくらnew()しようとGCも走りません。ただし、だからと言って必ずしも構造体の方が速いとは限らないので注意が必要です。(詳細は後述)
[余談] クラス/構造体のメモリ配置
ついで、と言っては何ですがクラスと構造体のメモリ配置についても触れておきましょう。C#ではほとんど意識することのないメモリ配置ですが、C/C++との相互運用やUnityのDOTSなどを扱う際に必要となるので覚えておいて損のない知識だと思います。
それでは、SharpLabを用いて実際にメモリ配置がどうなっているかを見ていきましょう。
クラスにおいて、各メンバのメモリ配置は不定です。例えば以下のようなクラスがあったとします。
class Sample
{
public byte a;
public long b;
public byte c;
}このクラスをインスタンス化してメモリ配置を確認すると、以下のようになります。

クラスの場合、まず最初にlockステートメント用のヘッダと型情報が入ります。それ以降が実際のデータになりますが、見ての通り宣言順に並んでいません。これはコンパイラが最適化のためにメモリ配置の調整(アラインメント)を行うためです。
一般的にメモリの読み書きは、アドレスが4の倍数や8の倍数の場合が高速です。そのため、コンパイラは効率的な読み書きを行うために「余白を開ける、配置を並び替える」等の処理を行います。
このクラスの場合、省スペースで綺麗な倍数にアドレスを揃えるには「a→b→c」と並べて間を空白で埋めるよりも「b→a→c」と並べた上で末尾に空白を開けた方が効率的です。そのため、宣言通りにならずこのような配置になっています。
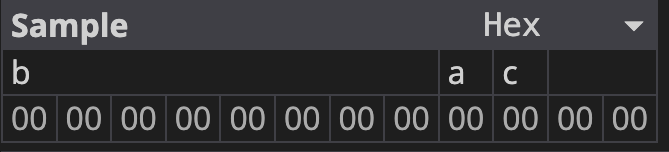
では、これが構造体の場合はどうなるでしょうか。先ほどのSampleを構造体に変えてみます。
// Sampleを構造体に変更
struct Sample
{
public byte a;
public long b;
public byte c;
}この構造体のメモリ配置は以下のようになります。

構造体の場合はヘッダに余計な情報が含まれておらず、またクラスとは違ってメンバのメモリ配置は宣言順と同じになります。さらに、アラインメントによってaとcの末尾に余白が追加されています。
少々無駄に思えるかもしれませんが、構造体の場合は順番に並んでいた方が何かと都合が良いためこのような配置になっています。
さらに配列の要素が構造体の場合、データはメモリ上に直列に並ぶことになります。(長くて収まらなかったので全てのフィールドをbyte型に変更しています)
struct Sample
{
public byte a;
public byte b;
public byte c;
}
var array = Sample[3];
lengthの後にデータが直列に並んでいるのがわかるかと思います。
また、クラスや構造体のメモリ配置は[StructLayout]属性と[FieldOffset]属性をつけることで変更が可能です。指定がない場合には、クラスは[StructLayout(LayoutKind.Auto)]、構造体は[StructLayout(LayoutKind.Sequential)]が適用されます。
では、試しに先ほどの構造体に[StructLayout(LayoutKind.Auto)]を追加してみましょう。
using System.Runtime.InteropServices;
[StructLayout(LayoutKind.Auto)] // 配置順の並び替えを許可する
struct Sample
{
public byte a;
public long b;
public byte c;
}
クラスの場合と同様に並び替えが行われ、サイズが小さくなりました。ただし、あくまでこれは例にすぎず、実際にStructLayoutを自分で指定する必要はほとんどないことに注意してください。これらの機能は相互運用等の特殊な用途においてのみ使用されます。
ここまでのまとめ
・メモリ管理にはスタックとヒープがある
・値型(構造体)はスタック、参照型(クラス)はヒープに置かれる
・メンバのメモリ配置は構造体は宣言順、クラスは不定
・構造体の配列はメモリが直列に並ぶ
クラスと構造体の使い分け
ここまでクラスと構造体の違いについて説明してきました。では、実際にコードを書く際にはどのような基準でこれらを使い分ければ良いのでしょうか。これについては、公式ドキュメントの「クラスまたは構造体の選択」という記事にガイドラインがあります。
以下は上の記事の引用になります。
経験則として、フレームワークのほとんどの型はクラスである必要があります。 ただし、場合によっては、値型の特性によって、構造体を使用する方が適切であることがあります。
✔️ 型のインスタンスが小さく、有効期間が短いことが多い場合、または他のオブジェクトに埋め込まれることが多い場合は、クラスではなく構造体を定義することを検討してください。
❌ 型が次のすべての特性を持つ場合を除き、構造体を定義することは避けてください。
・プリミティブ型 (int, double など) と同様に、論理的に単一の値を表す。
・インスタンスのサイズが 16 バイト未満である。
・不変である。
・頻繁にボックス化する必要がない。
その他すべての場合は、型をクラスとして定義する必要があります。
少々ややこしい文章ですが、このガイドラインの言いたいことは「上の4つの項を満たす場合には構造体、それ以外はクラスにしろ」ということです。
…ただこのガイドラインを忠実に全て守ろうとすると、構造体が使える場面が全くと言っていいほどなくなってしまうんですよね。実際.NETで構造体として定義されているものでもガイドラインのいずれかに違反していることが多いですし。(TimeSpanやDateTimeはちゃんとガイドライン通りですが、ValueTupleとか(.NETじゃないけど)Unityの構造体とかは完全に無視してる)
なのでこれはあくまで指標の一つとしつつ、もう少し緩い条件のもとで構造体を使うシチュエーションについて考えていきましょう。
インスタンスのサイズが十分に小さいこと
構造体がクラスに比べて有利に働く条件の一つとしては、インスタンスのサイズが十分に小さいことが挙げられます。
何度も書いている通り、構造体は値型であるため値渡しを行うたびにコピーが作成されます。そのため、サイズが大きければ大きいほどコピーのコストが嵩み性能が低下します。
そのため、ガイドラインにもあるように構造体のサイズは16バイト未満であることが推奨されます。このサイズを超えると、普通にクラスとして作って参照渡しした方が高速になります。(一応refとかポインタとかでコピーを避けるという手もあるんですが、これで全部やるのはあまり実用的ではないので…)
一応、メソッドに渡すことがなくコピーを行わない場面では16バイトを超えてもさほど問題はありませんが、基本的にサイズが大きいデータに対してはクラスを使った方が良いでしょう。
不変である
構造体は値型であるため、値が変更可能であると「変更したはずなのに変更されない」という混乱が起きてしまう、ということはVector3.Setの項目でも説明しました。特にプロパティと合わさると気づきにくく、なかなか厄介です。そのため、構造体は基本的に不変にしておくべきです。
ただ、オブジェクト内に埋め込む形で扱う場合などはコピーのコストが嵩むため、可変であることを許容する場合もあります。ただし、少なくとも構造体の中に値を変更するプロパティやメソッドは置かないことをお勧めします。
頻繁にボックス化される
値型をobjectに代入するボックス化は実質的にクラスのnew()と同じであり、値型の利点を完全に潰すことになります。また、ボックス化解除の負荷も考えると実質的にはそれ以上のコストになります。
そのため、構造体を扱う際はボックス化は徹底して避けるようにし、そもそもボックス化が避けられないなら最初からクラスにしておくようにしましょう。
ただし、このボックス化に関してはかなりの罠が存在し、気づかないうちにボックス化を引き起こしていることも多々あります。この辺りに関しては後ほど。
…結局いつ使うの?
上の項目だけ見ると「なんか大変そうだし、最初から全部クラスで良くない?」という感じがします。というかぶっちゃけ、大半のシチュエーションはクラスで何とかなります。
じゃあ実際どのような場面で使うかというと、プリミティブ型を2つ3つ持つだけ、みたいな「軽量なオブジェクトで、かつ頻繁にnew()されるもの」に対して効果を発揮します。UnityのVector3とかそういうやつ。
結論としては、基本的にはクラスを使いつつ、上のような小さなデータを扱う際にのみ構造体を使うのがベストでしょう。
あと、エクストリームな最適化を行う際には構造体をフル活用することが必須になります(MemoryPackみたいな高性能シリアライザだと可変な構造体バンバン使ってるし)。ただ、この辺りのテクニックが生きるのは性能重視のライブラリを作る時ぐらいなので、一般的な開発ではそこまでやる必要はなく、早すぎる最適化でしょう。
[余談] UnityのDOTSと構造体
上で構造体の基本的な指針について書きましたが、UnityのDOTS、とりわけECSに関してはこれは当てはまらないことが多いです。
ここでは詳しく触れませんが、UnityのDOTSは「データ指向」というオブジェクト指向とは別の考え方を使います。DOTSはデータをまとめて処理することで高いパフォーマンス実現するため、ほとんどのデータを構造体で扱うことになります。
そのため、DOTSでは上のような原則が通用しない場面が多々あります。内部ではunsafeな処理が多用され、Unity.Entitiesでは巨大な構造体を全てポインタで使い回す、といった実装も使われています。そもそもDOTSではC#の管轄外であるアンマネージドなメモリ領域を多く扱うため、あまりC#的ではなく、どちらかというと雰囲気はC++寄りです。
さらにはSourceGeneratorによるコード生成を多用するため、書いたコードがそのまま動くわけではない、ということも。Entities.ForEachとかIJobEntityとか。
C#的な常識が通用しないため難しいですが、非常にハイパフォーマンスな処理が全てC#で書ける、というのがDOTSの強みであり、面白さでもあります。Entitiesパッケージも1.0の登場によってかなり実用的になってきたので、Unityを扱う方であれば是非一度触ってみることをお勧めします。
ここまでのまとめ
・基本的にはクラスを用いる
・軽量で、かつ頻繁にnew()されるようなデータに構造体を用いる
・構造体は小さく、かつ不変にし、ボックス化は避ける
構造体に潜む罠とその対策
一応クラスと構造体の使い分けの結論を出して一段落、という流れでしたが、まだまだこの記事は終わりません。何せタイトルに「構造体(struct)を完全に理解する」などとつけてしまったので、細かいところまで徹底的に解説していきます。
というわけで、ここからは構造体を扱う上での注意点と、その対策方法についてを書いていきます。構造体はクラスと比較してとにかく罠が多いので…
ボックス化を徹底的に避ける
先ほども書きましたが、構造体を扱う上で大切なのは「ボックス化を避けること」です。そもそもパフォーマンスのために構造体を使用しているのに、ボックス化で余計なコストがかかってしまっては元も子もありません。
void SampleMethod(object obj)
{
// なんかする
}
// objectにint型を渡すのでボックス化する
SampleMethod(10);典型例としてはこのような感じです。引数がobject型のメソッドに対して値型を渡すとボックス化が発生します。ただし、実際にここまでわかりやすいボックス化が起きることは少ないでしょう。
しかし、構造体にはわかりづらいボックス化のパターンがいくつか存在します。
問題1: Equalsとボックス化
問題になりやすいのが以下のようなパターンです。
// 適当な構造体があって
struct Sample
{
public Sample(int a, int b)
{
this.a = a;
this.b = b;
}
public int a;
public int b;
}
// 適当に二つ用意
var sample1 = new Sample(1, 2);
var sample2 = new Sample(1, 2);
if (sample1 == sample2) // アウト。ここでボックス化が発生する
{
// なんかする
}Equalsはobject型を引数にとるためボックス化を引き起こします。また、構造体同士の比較はデフォルトの場合、ボックス化される上に全フィールドをリフレクションで比較するため非常に低速です。
さらに厄介なのが、DictionaryのKeyに構造体を使用した場合。
// ボックス化地獄を引き起こすDictionary
Dictionary<Sample, int> dangerousDictionary;こちらは内部でGetHashCode()とEquals()を呼び出すため、その過程でボックス化が発生します。
対策1: IEquatable<T>を実装し、GetHashCode()をoverrideする
この問題は、IEquatable<T>を実装し、かつGetHashCode()をoverrideすることで解決できます。
public interface IEquatable<T>
{
bool Equals(T other);
}Visual Studioの機能を使えば IEquatable<T>の自動実装が可能なので、実装に関しては省略します(というか実はさっきチラッと載せてたけど)。重要なのは、引数にobjectを介さないようにしてボックス化を回避することです。
また、こちらも同時に生成されますが、IEquatable<T>を実装する際は必ずセットでGetHashCode()の実装も行うようにしてください。
理想は全ての構造体に対してIEquatable<T>とGetHashCode()を実装することですが、流石に面倒なので等価判定を行う必要がある、またはDictionaryでKeyとして使われるものに対して実装するようにすれば良いでしょう。
問題2: インターフェースとボックス化
構造体はインターフェースの実装が可能ですが、構造体をインターフェースの型で受け取るとボックス化が発生します。具体的にはこんな感じ。
// 適当なインターフェース
public interface ISample
{
void Hoge();
}
// 適当な構造体
public struct SampleStruct : ISample
{
...
public void Hoge()
{
// なんかする
}
}
var sampleStruct = new SampleStruct();
// これは問題ない
sampleStruct.Hoge();
// これはアウト。ボックス化する
var sample = (ISample)sampleStruct;インターフェースの変数は参照型であるため、値型である構造体を代入しようとするとボックス化が発生します。
void CallHoge(ISample sample)
{
sample.Hoge();
}
var sampleStruct = new SampleStruct();
// アウト。もちろんこれもボックス化する
CallHoge(sampleStruct);当然メソッドの引数にしてもアウトです。問答無用でボックス化されます。
対策2: ジェネリック制約を用いる
この問題に対しては、ジェネリック制約を使うことで解決できます。先ほどのCallHoge()を以下のように変更します。
// ジェネリック制約で引数を受け取る
void CallHoge<T>(T sample) where T : ISample
{
sample.Hoge();
}
var sampleStruct = new SampleStruct();
// これはセーフ。ボックス化されない
CallHoge(sampleStruct);このようにジェネリックで引数を受け取ることによって、ボックス化・仮想メソッド呼び出しを回避しつつインターフェースの実装を呼び出すことが可能になります。
この手法はC#の最適化において有用なテクニックの一つなので、覚えておくと良いかもしれません。いやまあこんな最適化すること滅多にないけど…
readonlyと防衛的コピーの罠
構造体にはもう一つ避けるべき罠として、「防衛的コピー」というものが存在します。説明が難しいので、コードを先に示しましょう。
// 可変な構造体があるとする
// (てかそもそも可変な構造体を作るな)
struct MutableStruct
{
public int foo;
// fooを書き換えるメソッド
public int SetFoo(int value)
{
foo = value;
}
}
class Program
{
// readonlyなフィールドとして定義
readonly MutableStruct mutable = new MutableStruct();
static void Method1()
{
// 当然これはコンパイルエラーになる
mutable = new MutableStruct();
// 構造体の場合はこれもダメ
// フィールドもreadonlyを引き継ぐためコンパイルエラーになる
mutable.x = 1;
}
static void Method2()
{
// ではこれは?
mutable.SetFoo(1);
}
}readonlyなフィールドとして定義した場合、当然フィールドを書き換えることはできません。また、構造体をreadonlyなフィールドにした場合、中のフィールドに関してもreadonlyになります。(クラスの場合、中のフィールドは書き換えが可能なことに注意)
では、このreadonlyな構造体に中身を変更するメソッドがあった場合はどうなるのでしょうか。上のコードの場合、readonlyにも関わらず、SetFoo()で中身を書き換えられてしまうように見えます。
static void Method2()
{
// ここで書き換えを防ぐため、防衛的にコピーを作成する
mutable.SetFoo(1);
// つまり、以下のコードと同じ意味
var copied = mutable;
copied.SetFoo(1);
// そのため、元のフィールドの中身は書き変わっていない
Console.WriteLine(mutable.foo); // 0が表示される
}書き換えを防ぐため、構造体のreadonlyなフィールドに対してメソッド/プロパティ呼び出しが行われた場合には、自動的にコピーが作成されます。これが「防衛的コピー」です。これによって値が変更されないことを保証できますが、代わりにコピーによる余計な負荷が発生してしまいます。
さらに、この防衛的コピーは実際に書き換えが起きたかに関係なく、何らかのメソッド/プロパティ呼び出しが行われた時点で発生します。そのため、以下のようなコードでもコピーが作成されてしまいます。
struct MutableStruct
{
public int foo;
// fooを返すだけで、書き換えているわけではない
public int GetFoo()
{
return foo;
}
// 同様にfooを返すだけ
public int fooProperty
{
get
{
return foo;
}
}
}static void Method2()
{
// 先ほどと同様に、readonlyなmutableというフィールドがある
// 書き換えられてはいないが、ここでも防衛的コピーが発生する
var f1 = mutable.GetFoo(1);
// これも同様に防衛的コピーが発生する
var f2 = mutable.fooProperty;
}さらに、in引数(読み取り専用なref引数)と組み合わさることでも防衛的コピーは発生します。’in’はref引数と同じく値型を参照渡しできるためコピーが発生しませんが、メソッドやプロパティの呼び出しを行ってしまうと防衛的コピーが起こり、「参照渡ししてるはずなのに逆に性能が低下する」という事態が起こります。
// in引数は読み取り専用で値型を参照渡しする
static void Method(in Vector3 vector3)
{
// これはそもそもコンパイルエラーになる
vector3.x = 1;
// メソッドを呼び出すと防衛的コピーが発生する
vector3.Set(1, 2, 3);
// プロパティも同様にコピーが発生する
var m = vector3.magnitude;
}readonly structを使おう
この防衛的コピーは、readonly structを使うことで対策が可能です。
// readonly structとして定義
readonly struct ROStruct
{
// 全てのフィールドをreadonlyにする必要がある
public readonly int foo;
public readonly int bar;
public void Hoge() { }
}readonly structとして定義しておくことで、読み取り専用であることを保証できるため防衛的コピーは発生しなくなります。
class Program
{
readonly ROStruct ro = new ROStruct();
static void Method1()
{
// readonly structであるため防衛的コピーは発生しない
ro.Hoge();
}
static void Method2(in inStruct)
{
// 'in'で渡しても防衛的コピーは発生しない
inStruct.Hoge();
}
}このようにメソッド呼び出しを行なってもコピーは発生しません。防衛的コピーはパフォーマンスの低下につながるので、特に大きめの構造体を扱う際には気をつけましょう。
また、in引数を使うと防衛的コピーを引き起こしやすいので、構造体をin引数で渡す際は原則readonly structのみとしておくと良いでしょう。in引数は少々扱いが難しいので、そもそも使わないことも一つの手です。
ここまでのまとめ
・IEquatable<T>を実装してEqualsのボックス化を避ける
・インターフェースはジェネリック制約を介してボックス化を避ける
・readonly structで防衛的コピーを防ぐ
今日から使える構造体たち
ここまでの内容は独自に構造体を作成する際の注意点でしたが、実際に自分で構造体を定義して使うシチュエーションはそこまで多くありません。そこで最後に、もう少し実用的な話として実際に構造体として定義されている便利な機能を紹介して終わりたいと思います。ここの知識に関してはすぐに使えるはずなので是非。
タプル (ValueTuple)
C#にはタプルという機能があり、複数の値を持つ名無しの構造体をその場で定義することができます。
// 名前のない構造体としてタプルが利用できる
(int x, int y) tuple1 = (1, 2);
// こんな感じで利用できる
Console.WriteLine(tuple1.x);
Console.WriteLine(tuple1.y); ここではメンバ名を明示していますが、省略することも可能です。
// メンバ名を書かなくても良い
(int, int) tuple2 = (1, 2);
// Item1、Item2...という名前でアクセス可能
Console.WriteLine(tuple2.Item1);
Console.WriteLine(tuple2.Item2);
// 型推論も効く
var tuple3 = (1, 2);関数の戻り値にタプルを用いることで、複数の値を同時に返すことも可能です。
// タプルを戻り値に持つ
(int, float) GetTwoValues()
{
return (1, 2.5f); // 適当に値を返してみる
}
var result = GetTwoValue();
Console.WriteLine(result.Item1); // 1
Console.WriteLine(result.Item2); // 2.5また、タプルを用いることで値の入れ替えを簡単に行うことも可能です。この辺りはUnity Japanの動画で解説されていましたね。
int a = 1;
int b = 2;
// 普通にやると面倒な値の入れ替えも...
int temp = a;
a = b;
b = temp;
// タプルならこれだけ
(a, b) = (b, a);また、値の比較にタプルを用いることも可能です。もちろんボックス化が起こるようなことはなく、コンパイラによってメンバ同士の比較に展開されます。
bool IsSame((int, int) a, (int, int) b)
{
return a == b;
// 実際には以下のような形に展開される
// return a.Item1 == b.Item1 && a.Item2 == b.Item2;
}では、このタプルの内部はどのようになっているかというと、System.ValueTupleという構造体に展開されます。
// このようなコードがあったとして...
var tuple = (x: 1, y: 2);
Console.WriteLine(tuple.x);
Console.WriteLine(tuple.y);
// 実際は以下のような形に展開される
var tuple = new System.ValueTuple<int, int>(1, 2);
Console.WriteLine(tuple.Item1);
Console.WriteLine(tuple.Item2);タプルの宣言時につけたメンバ名は、コンパイル時には消失します。メンバ名が何であろうと内部的には同じValueTuple型であるため、型の数と順番さえあっていればメンバ名の違うタプルにも代入可能です。
// 名前は違うが型の数・順番は同じなタプル
(int x, int y) tuple1 = (1, 2);
(int a, int b) tuple2 = (3, 4);
// 問題なく代入が可能
tuple1 = tuple2;
// 3が表示される
Console.WriteLine(tuple1.x);非常に有用な機能で、言語機能として組み込まれているため書き心地も引数に近くとても良いです。簡単に使えるので是非とも活用していきましょう。
Span<T>、ReadOnlySpan<T>
Span<T>は配列など、特定のメモリ領域の読み書きを行うため構造体です。Span<T>は読み書きの両方が行えるのに対し、ReadOnlySpan<T>はその名の通り読み取りのみに制限されます。
例えば、配列の一部を読み取りたい場合。普通にやると以下のようになります。が…
// 適当なint配列を用意
int[] array = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// これはNG。Sliceを使うと新たな配列を作成して返すため、余計なアロケーションが発生する
foreach (var i in array.Slice(2, 4)) { }
// これもSliceに展開されるのでNG
foreach (var i in array[2..6]) { }Sliceは新たな配列を作成するため、余計なアロケーションが発生します。そのため、単に一部の読み取りを行う場合には不向きです。
そこで、AsSpan()を用いてSpan<int>に変換します。Spanを経由することでコピーを回避します。また、Spanは特殊な最適化がかかるため、高速な読み取りを可能にします。
// 適当なint配列を用意
int[] array = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// AsSpan()を挟むことでコピーを回避する
foreach (var i in array.AsSpan().Slice(2, 4)) { }
// これも同じ
foreach (var i in array.AsSpan()[2..6]) { }これらは文字列に適用することも可能です。
// 適当なstring
string str = "0123456789";
// Substringは新たなstringを作成してしまう
foreach (var i in str.Substring(2, 4)) { }
// AsSpanを挟んでコピーを回避
foreach (var i in str.AsSpan().Slice(2, 4)) { }またここでは触れませんが、Spanはスタック領域やアンマネージドなメモリ領域を指すことも可能です。そのため、生データを扱う際や相互運用などにも非常に有用です。
[余談] List<T>.Enumerator
こちらはあまり実用的な話ではないので余談になりますが、List<T>の列挙に関しては面白い最適化が施されています。
// どっかに適当なListがあるとする
List<int> list;
// foreachではGetEnumerator()を呼ぶので、アロケーションが発生する
// が、List<T>の場合はゼロアロケーション
foreach (var i in list) { }foreachは実質的にはGetEnumerator()で列挙子を取得してwhile内でMoveNext()する処理なので、IEnumeratorの生成時にアロケーションが発生します。(ただし、配列のforeachはforに展開される)
しかし、これがList<T>の場合にはアロケーションが発生しません。なぜか、というのは実装を見ればわかります。
// List<T>内部に定義されている構造体
public struct Enumerator : IEnumerator<T>, IEnumerator
{
private readonly List<T> _list;
private int _index;
private readonly int _version;
private T _current;
...
}List<T>の列挙にはList<T>.Enumeratorという構造体が使われます。そう、構造体です。
このList<T>.EnumeratorはMutable(可変)であり、一般的な構造体のガイドラインに真っ向から反しています。しかし、実際これが構造体で実装されていることにより、foreachを使う際にゼロアロケーションを実現できます。
このように「アロケーションを発生させない一時的な入れ物」を実装するには可変な構造体(Mutable Struct)が有用である場面もあります。あまり一般的ではなく使える場面は限定されますが、知っておくと良いかもしれません。
まとめ
今回の記事はここまでですが、いかがだったでしょうか。いや、長い。マジで長い。それはそう、なんですが、おかげで「構造体完全に理解した」と言えるくらいには構造体について学べたのではないでしょうか。
ただし、この記事では紹介されていない構造体の機能もまだ存在します。この記事で触れていない機能としてはref structなどでしょうか。ほんとは紹介したかったんですが…使うことほぼないし流石に長いので…
「いますぐ構造体使おう!」というのはなかなか難しいし、構造体が有用な場面というのもそこまで多くはありません。しかし、パフォーマンスが求められる場面に遭遇した際に備えて、知っておくべき知識なのは間違いないでしょう。
構造体を知り尽くし、そして使いこなしていきましょう。

ピンバック: 【Unity】NativeArrayを使いこなせ - Annulus Games
ピンバック: 【C#】unsafeコードを書いてみよう - Annulus Games